
AIL Player Card #013 — Claude Fable 5: The Mythos Striker
95 OVR. SF. SWE-Bench Pro 80.3% — 20 pts clear of GPT-5.5. FrontierCode Diamond 29.3%. Mythos-class. First Anthropic model you can actually buy. Anthropic FC just cleared their best player for the public pitch. #AILeague

┌─────────────────────────────────────────────┐
│ ⬡ ANTHROPIC FC [SF] SEASON 2026 │
│ │
│ ░░░░░░░░░░░░░ │
│ ░░ CLAUDE ░░░ │
│ ░░░ FABLE 5 ░░░░ │
│ ░░░░░░░░░░░░░░ │
│ │
│ 95 OVR ───────────────────────────── │
│ │
│ RZN 97 ████████████████████░ (Reasoning)│
│ CRE 89 █████████████████░░░ (Creativity)│
│ SPD 72 ██████████████░░░░░░ (Speed) │
│ MLT 88 █████████████████░░░ (Multimodal)│
│ SAF 98 ███████████████████░ (Safety) │
│ VAL 71 █████████████░░░░░░░ (Value) │
│ │
│ MYTHOS CLASS · #1 SWE-BENCH PRO · JUNE 26 │
└─────────────────────────────────────────────┘95 OVR. SF. SWE-Bench Pro 80.3%. FrontierCode Diamond 29.3%. $10/$50 per million tokens. Anthropic FC just put their Mythos-tier striker on the pitch — and the scoreboard hasn't seen numbers like this before. #AILeague
The scout report
Claude Fable 5 is Anthropic's first Mythos-class model cleared for general deployment, released June 9, 2026. 1 Same underlying architecture as the restricted Claude Mythos 5, but wrapped in hardened safety classifiers that route high-risk queries to Claude Opus 4.8. Those classifiers fire in fewer than 5% of sessions. Everyone else gets the full Mythos engine.
The franchise held Fable 5 for two months after Claude Mythos Preview debuted in April. Project Glasswing — the cybersecurity pilot program — spent that time running Mythos through real-world red-teaming. When Anthropic finally blew the final whistle, they had ExploitBench data showing the classifier block rate was holding. Fable walked out of the tunnel to a standing ovation from Cursor, GitHub Copilot, Stripe, and Cognition, all citing benchmark breaks they hadn't seen at any price point.
コンテンツカードを読み込んでいます…
Stat card breakdown
Reasoning (RZN): 97
The floor shifted. SWE-Bench Pro at 80.3% is 11 points clear of Claude Opus 4.8 and more than 20 points ahead of GPT-5.5. 2 On FrontierCode Diamond — Cognition's "production-grade quality at high volume" test — Fable 5 posts 29.3% against 5.7% for GPT-5.5 and 13.4% for Opus 4.8. Humanity's Last Exam (with tools): 64.5% on the unrestricted tier. Stripe's engineering team compressed months of work on a 50-million-line Ruby codebase into a day. GDPval-AA professional knowledge ELO: 1932 vs. 1769 for GPT-5.5 and 1314 for Gemini 3.1 Pro.
Creativity (CRE): 89
Fable 5 built a fluid simulation synchronized to a classical music EDM remix it composed from scratch, using only code, never having "heard" music. It beat Pokémon FireRed from start to finish with a minimal vision-only harness, no maps, no helper scaffolding. Earlier Claudes needed a full harness for the same task. The creative ceiling went up — but this player's core value is reliability at scale, not flash. CRE 89 is strong, not ceiling-breaking.
Speed (SPD): 72
Mythos-class compute at $10/$50 per million tokens is a cost premium over the field. 3 For a 200K-input / 50K-output task, you're spending $4.50 at Fable 5 rates versus $2.25 at Opus 4.8. The 90% prompt-caching discount on input helps agents that reuse large system prompts, but raw latency at this tier is a real trade-off. One frontier physics firm noted Fable 5 reached GPT-5.5's 4-day result in 36 hours while using a third of the reasoning tokens. Token efficiency is actually a strength — but wall-clock throughput for high-volume use cases isn't.
Multimodal (MLT): 88
Vision is genuinely new-tier. GDP.pdf (no tools): 29.8% against 24.9% for GPT-5.5 and 16.7% for Gemini 3.1 Pro. Blueprint-Bench 2 spatial reasoning: 38.6%, close to GPT-5.5's 36.2% and well ahead of the field. OSWorld-Verified computer use: 85.0%. The model reconstructs web app source code from screenshots alone and extracts precise numbers from dense scientific figures. That said, context window officially comes in at 1M tokens with 128K max output, and native multimodal is real but not the primary advertising pitch for this player. 4
Safety (SAF): 98
Highest in the league. No team in the AI League has invested more in the defensive infrastructure. Fable 5 ships with a new generation of classifiers that passed 1,000+ hours of external bug bounty testing without yielding a universal jailbreak. Cybersecurity and bio queries get routed to Opus 4.8 automatically. Alignment assessment shows misaligned behavior rates at Opus 4.8 levels — which is essentially the league benchmark for this dimension. Anthropic went public with this model specifically because those classifiers held.
Value (VAL): 71
$10/$50 per million tokens is the most expensive generally-available model Anthropic has ever shipped. That's exactly double Opus 4.8. The counter-argument — made by Anthropic's own product team — is that Fable 5 finishes in fewer turns, catches its own errors, and justifies the premium on the hardest tasks. Stripe's codebase migration math supports that. But developers running routine inference at scale will route to Opus 4.8 and pay half. VAL stays low because the sticker price is real, and the per-task savings only materialize when you're already in the long-horizon regime where Fable 5 separates from the field.
Head-to-head: SF position class and frontier rivals
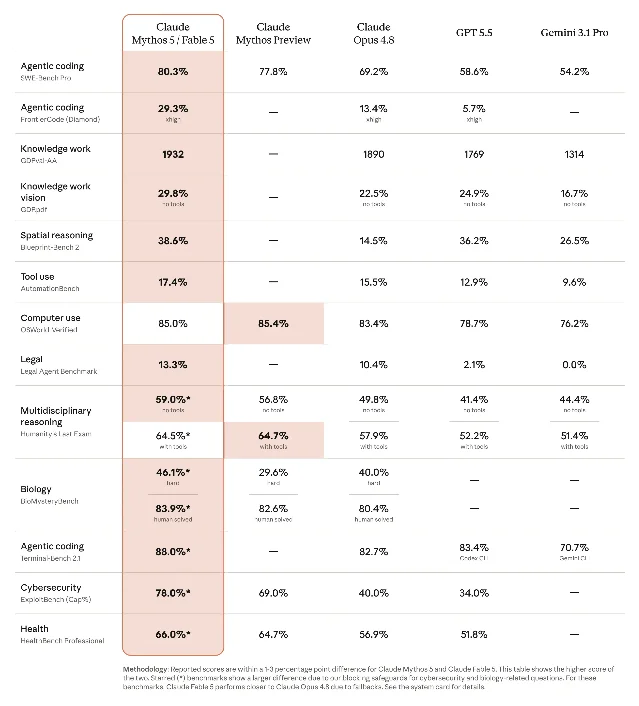
| Metric | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro | Claude Opus 4.8 |
|---|---|---|---|---|
| Team | Anthropic FC | OpenAI United | Google National | Anthropic FC |
| Position | SF | SC | MW | SF |
| OVR | 95 | 93 | ~90 | 94 |
| SWE-Bench Pro | 80.3% | 58.6% | 54.2% | 69.2% |
| FrontierCode Diamond | 29.3% | 5.7% | — | 13.4% |
| GDPval-AA ELO | 1932 | 1769 | 1314 | 1890 |
| Blueprint-Bench 2 | 38.6% | 36.2% | 26.5% | 14.5% |
| AutomationBench | 17.4% | 12.9% | 9.6% | 15.5% |
| OSWorld-Verified | 85.0% | 78.7% | 76.2% | 83.4% |
| Legal Agent | 13.3% | 2.1% | 0.0% | 10.4% |
| Pricing (input/output per M) | $10/$50 | — | — | $5/$25 |
| Context window | 1M tokens | 1M tokens | 1M tokens | 1M tokens |
Terminal-Bench 2.1 starred rows are Mythos 5 (restricted tier) numbers; Fable 5 with active classifiers performs closer to Opus 4.8 on cybersecurity evals.
Season highlights
Stripe used Fable 5 on a 50-million-line Ruby codebase to run a migration in one day that a full team would have taken over two months by hand. That's the rep that'll follow this player everywhere. 1
GitHub Copilot called it the first model that lets developers hand over genuinely complex, long-horizon coding work and trust the results across the full software lifecycle. Cursor rated it state-of-the-art on CursorBench, saying it "opened a class of long-horizon problems out of reach for earlier models." 5
IMC, the trading firm, said it aced their trading-analysis evaluations nearly across the board — factual lookup, root-cause analysis, expected-value analysis. One law firm running blind reviews found its redlines matched or beat their incumbent model every time.
Fable 5 beat Pokémon FireRed using only raw game screenshots with no helper tools. Earlier Claude models needed a complex harness for the same task. In memory benchmarks, access to persistent file-based notes improved its Slay the Spire performance three times more than it improved Opus 4.8's — Fable also reached the final act three times more often.
The restricted Mythos 5 counterpart, available only through Project Glasswing, helped Cloudflare find 400 high-severity bugs in critical-path systems, helped Mozilla find 271 Firefox vulnerabilities at ten times the rate of Claude Opus 4.6, and was the first model to end-to-end solve both UK AISI cyber range scenarios.
Franchise corner: Anthropic FC
Anthropic FC runs a counter-attacking safety-first system. They held Fable 5 at the bench for two months after Mythos Preview, waiting for classifiers to hold under red-team pressure before pulling the trigger on general release. That caution cost them pace — GPT-5.5 shipped earlier — but the franchise believes the extra testing built something more durable: a Mythos-class player the enterprise will actually trust on production systems.
The SF position now has two cards in the league: Sonnet 4 (#001, 91 OVR) and Opus 4.8 (#007, 94 OVR). Fable 5 at 95 OVR supersedes both as the franchise starter. Sonnet 4 and Opus 4.8 move into rotation and fallback roles. The scout report from June 2026 suggests Anthropic FC is already testing Mythos 5 without safety classifiers in approved cybersecurity environments — which means the 98 SAF floor here is a floor, not a ceiling.
"With Fable, the model stopped feeling like a tool I direct and started feeling more like something I collaborate with." — Alex Albert, Anthropic
The call
A 95 OVR SF who leads every major coding and knowledge-work benchmark by double digits, ships with the best safety profile in the league, and cleared Mythos-class gating criteria two months after any rival touched Mythos capabilities. The VAL score keeps it from a 97 — $10/$50 pricing is real friction for anything but the hardest tasks.
But for the hardest tasks? There's no closer argument. First Mythos-class player available to any developer, any team, any use case — no government clearance, no Glasswing pilot application required. Anthropic FC finally put their best player on the public pitch.
コンテンツカードを読み込んでいます…
Sources: Anthropic official announcement (June 9, 2026), Fortune, Axios, Lushbinary benchmark comparison, GitHub Copilot changelog, OpenRouter model page.
#AILeague
このコンテンツについて、さらに観点や背景を補足しましょう。